Alex
Concurrent File Processing Example (Video 27)
- This example walks through a CSP style concurrent program for finding duplicate files based on their content
- This first example is a simple sequential implementation with no concurrency:
type pair struct {
hash, path string
}
type fileList []string
type results map[string]fileList
// calculate the hash of a specific file path, returning a pair of
// (hash, path)
func hashFile(path string) pair {
file, err := os.Open(path)
if err != nil {
log.Fatal(err)
}
defer file.Close()
hash := md5.New()
if _, err := io.Copy(hash, file); err != nil {
log.Fatal(err)
}
return pair{fmt.Sprintf("%x", hash.Sum(nil)), path}
}
// this is a sequential implementation, could be quite slow on a large directory
func walk(dir string) (results, error) {
hashes := make(results)
err := filepath.Walk(dir, func(path string, fi os.FileInfo, err error) error {
if fi.Mode().IsRegular() && fi.Size() > 0 {
h := hashFile(path)
hashes[h.hash] = append(hashes[h.hash], h.path) // add the new file path to it's corresponding hash entry in the map
}
return nil
})
return hashes, er r
}
Concurrent Approaches
- All of the examples shown below are generically called map-reduce
Worker Pool
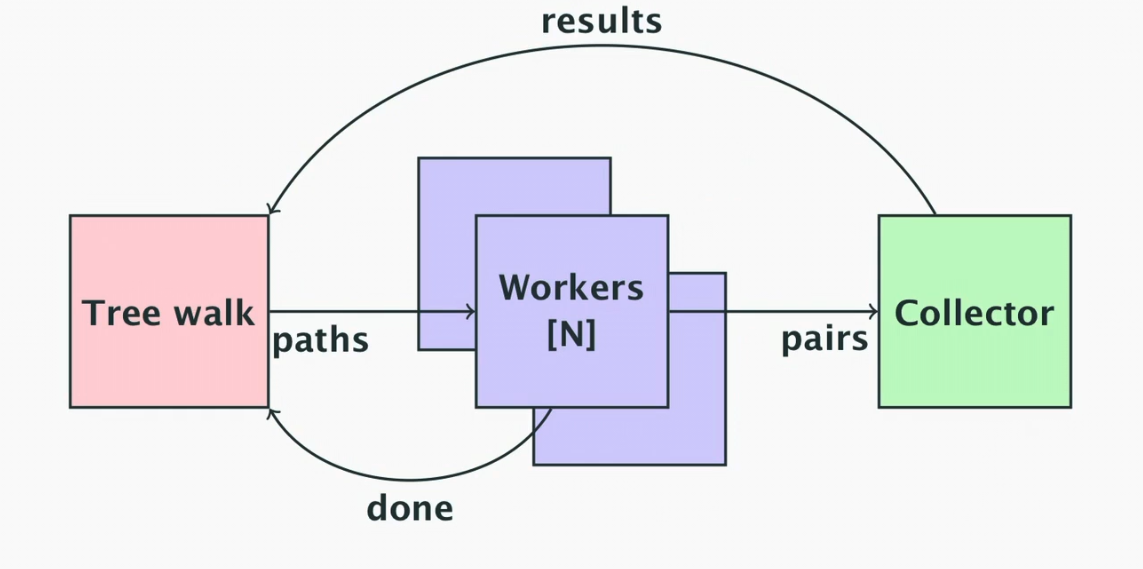
- The above diagram shows the model for the worker pool implementation
- The main method will feed N workers with paths to process, then will watch for the workers being done
- This is so that the pairs channel can be closed when the workers are finished, since we can’t delegate that work to the workers since they can’t coordinate who’s finished last
- The workers will run in independent goroutines
- A collector will watch the output pairs from the workers and return them to the main method on a results channel
- We tell the workers we are done by closing the paths channel
- They will stop working once they’ve processed their last file(s)
func collector(pairs <-chan pair, result chan<- results) {
hashes := make(results)
// loop will only stop when the channel closes
for p := range pairs {
hashes[p.hash] = append(hashes[p.hash], p.path)
}
result <- hashes
}
func worker(paths <-chan string, pairs chan<- pair, done chan<- bool) {
// process files until the paths channel is closed
for path := range paths {
pairs <- hashFile(path)
}
done <- true
}
func main() {
numWorkers := 2 * runtime.GOMAXPROCS(0)
// the first model has unbuffered channels
paths := make(chan string)
pairs := make(chan pair)
done := make(chan bool)
result := make(chan results)
for i := 0; i < numWorkers; i++ {
go processFiles(paths, pairs, done)
}
go collectHashes(pairs, result)
err := filePath.Walk(fir, func(path string, fi os.FileInfo, err error) error {
if fi.Mode().IsRegular() && fi.Size() > 0 {
paths <- p
}
return nil
})
if err != nil {
log.Fatal(err)
}
// so the workers stop
close(paths)
for i := 0; i < numWorkers; i++ {
// we then read from the done channel until all workers are done
<-done
}
// after all the workers are done we can close the pairs channel
close(pairs)
// finally we can read the hashes from the result channel
hashes := <-result
fmt.Println(hashes)
}
Goroutine for Each Directory in the Tree Approach
- Instead of a worker pool, we start a goroutine for each directory in the tree
- For this we use the waitgroup
- We add to the waitgroup when we start a unit of work, then wait until all work units
wg.Done()and the counter will be 0
func searchTree(dir string, paths chan<- string, wg *sync.WaitGroup) error {
defer wg.Done()
visit := func(p string, fi os.FileInfo, err error) error {
if err != nil && err != os.ErrNotExist {
return err
}
// ignore dir itself to avoid an infinite loop
if fi.Mode().IsDir() && p != dir {
wg.Add(1)
go searchTree(p, paths, wg) // we recursively search the tree in new goroutines to speed up listing
return filepath.SkipDir
}
if fi.Mode().IsRegular() && fi.Size() > 0 {
paths <- p
}
return nil
}
return filepath.Walk(dir, visit)
}
func run(dir string) results {
workers := 2 * runtime.GOMAXPROCS(0)
paths := make(chan string)
pairs := make(chan pair)
done := make(chan bool)
result := make(chan results)
wg := new(sync.WaitGroup)
for i := 0; i < workers; i++ {
go processFiles(paths, pairs, done)
}
go collectHashes(pairs, result)
// multi-threaded walk of the directory tree
wg.Add(1)
err := searchTree(dir, paths, wg)
if err != nil {
log.Fatal(err)
}
// wg.Wait() will block until all the directory listing work is done
wg.Wait()
close(paths)
for i := 0; i < workers; i++ {
<-done
}
close(pairs)
return <-result
}
- The above implementation is mostly the same except the directory walking is now multithreaded as well
- There are marginal performance gains for doing this
No Workers - Just Goroutine for Each File and Directory
- The final approach uses a goroutine for each file and directory
- We have to be careful, GOMAXPROCS doesn’t limit the number of threads that are blocked on syscalls (e.g. I/O), meaning that if we spawned 10000 goroutines that all try and do IO, Go will actually create 10000 threads which is not great
- To limit the work, we can use a channel as a counting semaphore; a channel with buffer size N can accept N sends without blocking
- So we can have one goroutine start for each one that finishes (where each reads from the channel when complete)
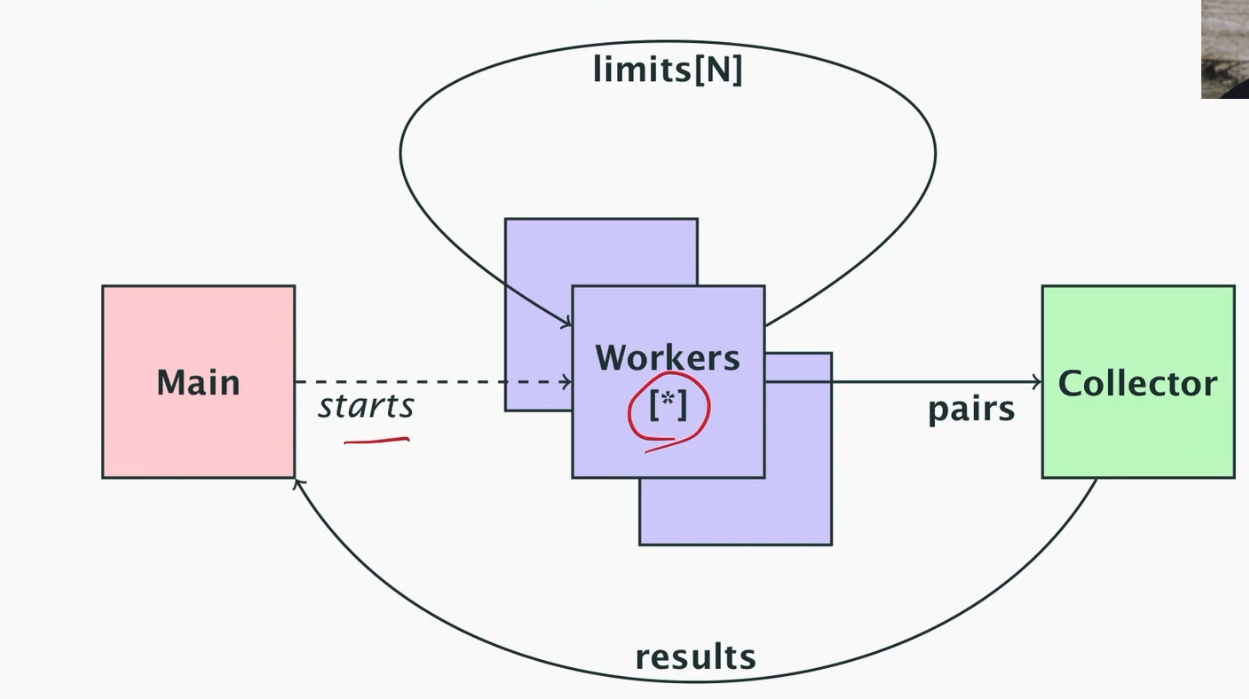
- Now we have a slightly different program structure where goroutines are limited by a higher limit N rather than having a fixed number of workers
func processFile(path string, pairs chan<- pair, wg *sync.WaitGroup, limits chan bool) {
defer wg.Done()
// writing to limits will block until another processFile goroutine finishes
limits <- true
// this is the point that the goroutine is finished (defered). reading from the channel will free up a slot for another goroutine
defer func() {
<-limits
}()
pairs <- hashFile(path)
}
func collectHashes(pairs <-chan pair, result chan<- results) {
hashes := make(results)
for p := range pairs {
hashes[p.hash] = append(hashes[p.hash], p.path)
}
result <- hashes
}
func walkDir(dir string, pairs chan<- pair, wg *sync.WaitGroup, limits chan bool) error {
defer wg.Done()
visit := func(p string, fi os.FileInfo, err error) error {
if err != nil && err != os.ErrNotExist {
return err
}
// ignore dir itself to avoid an infinite loop!
if fi.Mode().IsDir() && p != dir {
wg.Add(1)
go walkDir(p, pairs, wg, limits)
return filepath.SkipDir
}
if fi.Mode().IsRegular() && fi.Size() > 0 {
wg.Add(1)
go processFile(p, pairs, wg, limits)
}
return nil
}
// again since this walkDir is also IO bound, we have this functionality to wait on the limits channel
// until a slot opens
limits <- true
defer func() {
<-limits
}()
return filepath.Walk(dir, visit)
}
func run(dir string) results {
workers := 2 * runtime.GOMAXPROCS(0)
limits := make(chan bool, workers)
pairs := make(chan pair)
result := make(chan results)
wg := new(sync.WaitGroup)
// we need another goroutine so we don't block here
go collectHashes(pairs, result)
// multi-threaded walk of the directory tree; we need a
// waitGroup because we don't know how many to wait for
wg.Add(1)
err := walkDir(dir, pairs, wg, limits)
if err != nil {
log.Fatal(err)
}
// we must close the paths channel so the workers stop
wg.Wait()
// by closing pairs we signal that all the hashes
// have been collected; we have to do it here AFTER
// all the workers are done
close(pairs)
return <-result
}
func main() {
if len(os.Args) < 2 {
log.Fatal("Missing parameter, provide dir name!")
}
if hashes := run(os.Args[1]); hashes != nil {
for hash, files := range hashes {
if len(files) > 1 {
// we will use just 7 chars like git
fmt.Println(hash[len(hash)-7:], len(files))
for _, file := range files {
fmt.Println(" ", file)
}
}
}
}
}
- Code reproduced from github.com/matt4biz/go-class-walk/blob/trunk/walk3/walk3.go
Amdahl’s Law
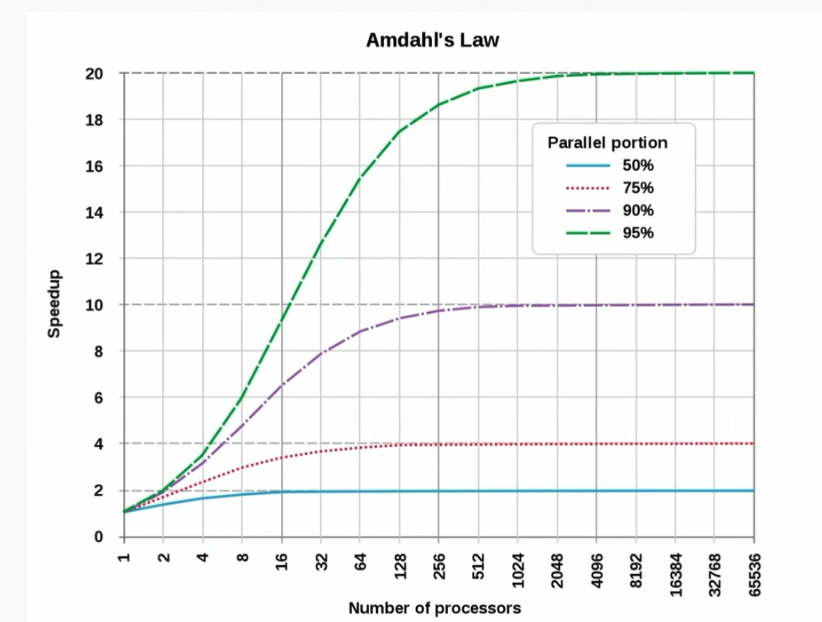
- Amdahl’s law states that the speedup in a program is limited by the proportion that is not parallelised
- See how the more you can parallelise your program the more performance speedup you get, up to a limit defined by the number of processors
- The biggest limit for the examples above was resource contention - disk accesses are slow and no amount of parallelisation will fix that